winterjung blog
파이썬에서 2중 리스트를 flatten하게 만들기
우연히 커뮤니티의 프로그래밍 게시판에서 파이썬의 2중 리스트 를 일자화 시키는 것에 대해 보게되었다.
2중 리스트를 1차원 리스트로 만드는 방법은 몇 개 알고 있었는데 어떤 댓글에서 sum(numbers, [])라는 식으로 2중 리스트를 일자화 시키는 것을 보고 전혀 알지 못했던 트릭이라 신기했다.
동작 원리를 설명할 겸 다른 flatten 방식도 살펴보자.
여러 방법들
list_of_lists = [[1, 2], [3, 4]] 라는 (2, 2) 형상의 list가 있다고 가정하면
이 list를 [1, 2, 3, 4]의 1차원 리스트로 만드는 방법은 여러가지가 있다.
itertools.chain()
파이썬의 표준 라이브러리 중 itertools에는 iterable한 컨테이너랑 쓸 수 있는 여러 유용한 함수가 존재한다.
이 중 itertools.chain()이라는 함수는 인자로 받은 iterator들의 원소를 연결해 반환하는 함수이다.
def chain(*iterables):
# chain('ABC', 'DEF') --> ['A', 'B', 'C', 'D', 'E', 'F']
for it in iterables:
for element in it:
yield element
하지만 여기에 바로 list_of_lists를 전달한다고 우리가 원하는 1차원 리스트를 얻을 수 없다.
chain()함수는 인자들을 엮어주는 것이므로 하나의 list만 달랑 던져주면 던져준 그대로 2차원 리스트를 반환하며 원하는 대로 작동하진 않는다.
>>> list_of_lists = [[1, 2], [3, 4]]
>>> list(itertools.chain(list_of_lists))
[[1, 2], [3, 4]]
이 때 원하는 결과값인 [1, 2, 3, 4]를 얻기 위해선 앞에 *(asterisk)을 붙여주어 전달해야한다.
그러면 iterable한 컨테이너 테이터를 언패킹하여 전달한다.
>>> list_of_lists = [[1, 2], [3, 4]]
>>> list(itertools.chain(*list_of_lists))
[1, 2, 3, 4]
추가로 *(asterisk)의 다양한 쓰임새는 mingrammer님의 파이썬의 Asterisk(*) 이해하기글에서 확인할 수 있다.
itertools.chain.from_iterable()
위의 귀찮음을 피하고자 from_iterable 메서드가 존재한다.
def from_iterable(iterables):
# chain.from_iterable(['ABC', 'DEF']) --> ['A', 'B', 'C', 'D', 'E', 'F']
for it in iterables:
for element in it:
yield element
앞의 예제 처럼 하나의 iterator만 전달해도 iterator의 element들을 조회하면서 lazy하게 넘겨주는 것을 확인할 수 있다.
>>> list_of_lists = [[1, 2], [3, 4]]
>>> list(itertools.chain.from_iterable(list_of_lists))
[1, 2, 3, 4]
리스트 컴프리헨션 (list comprehension)
어찌보면 phtonic하다고 볼 수도 있는데 개인적으로는 코드가 그리 직관적으로 다가오진 않는다.
>>> list_of_lists = [[1, 2], [3, 4]]
>>> [y for x in list_of_lists for y in x]
[1, 2, 3, 4]
원래 컴프리헨션은 가독성을 높이는 기법이라고 생각하는데 이런 2차원 리스트를 1차원 리스트로 만들 때는 별로 가독성이 높아지지 않는 것 같다.
[y for x in list_of_lists for y in x]이렇게 구문이 주어지면for x in list_of_lists구문이 먼저 해석되어list_of_lists의 element들이 각각 x에 들어가게되고[y for y in x]구문이 해석되어 각각의 x에 들어있는 element들이 y로 조회되고 최종적으로 y로 이루어진 1차원 리스트가 생성된다.
그나마 좀 더 알아보기 쉽게 하자면 [second for first in list_of_lists for second in first]정도인데 그게 그거 같다.
sum()
이런 방법이 있는줄 처음 알게된 기법이다.
>>> list_of_lists = [[1, 2], [3, 4]]
>>> sum(list_of_lists, [])
[1, 2, 3, 4]
본래 sum함수는 built-in functions 문서를 참고하면 sum(iterable[, start])의 형태를 띄고있고, start와 iterable의 items를 더해 반환하는 함수이다.
보통 sum([1, 2, 3, 4])같은 형태로 sum을 사용할 때 iterable이 [1, 2, 3, 4]이고 디폴트로 지정된 start의 값은 0인 셈이다.
sum([[1, 2], [3, 4]])같은 식으로 사용하면 2차원 리스트의 원소들인 [1, 2]와 [3, 4]가 더해져 [1, 2, 3, 4]가 되는게 아니냐 할 수 있는데 start의 값이 디폴트로 0이기 때문에 저런식으로 그냥 전달해 버리면 TypeError: unsupported operand type(s) for +: 'int' and 'list'처럼 int에 list를 더할 수 없다는 TypeError가 발생한다.
start가 맨 왼쪽에서 더해지는 대상이기 때문에 list에 int를 더할 때 발생하는TypeError: can only concatenate list (not "int") to list에러 메시지가 아닌 것이다.
그래서 sum([[1, 2], [3, 4]], [])의 형태로 사용해야 [] + [1, 2] + [3, 4]로 해석되어 우리가 원하는 1차원 리스트를 구할 수 있는 것이다.
그 외
>>> list_of_lists = [[1, 2], [3, 4]]
>>> result = []
>>> for item in list_of_lists:
result.extend(item)
>>> result
[1, 2, 3, 4]
같은 식으로 for문으로 돌려서 extend 시키거나 + 시킬 수도 있겠지만 이는 논외로 치겠다.
저 두 줄로 나뉘어진 구문도 리스트 컴프리헨션으로 한줄로 줄일 수 있겠으나 [b.extend(x) for x in a]의 형태는 [None, None]을 반환하고 외부 변수인 b를 변형시키기 때문에 적절하지 않다고 생각한다.
성능 비교
간단하게 4가지의 방법을 비교해 보겠다.
itertools.chain()itertools.chain.from_iterable()- 리스트 컴프리헨션
sum()
from itertools import chain
list_of_lists = [[x, 0] for x in range(10000)]
%timeit list(chain(*list_of_lists))
# 1000 loops, best of 3: 491 µs per loop
%timeit list(chain.from_iterable(list_of_lists))
# 1000 loops, best of 3: 429 µs per loop
%timeit [y for x in list_of_lists for y in x]
# 1000 loops, best of 3: 725 µs per loop
%timeit sum(list_of_lists, [])
# 1 loop, best of 3: 211 ms per loop
결과를 보면 sum()함수만 끔찍하게 느리고 나머지 셋은 고만고만함을 알 수 있다.
성능과 가독성 중 무엇을 중시하냐의 차이지만 개인적으로 itertools.chain() 자체도 가독성이 나쁘다고 볼 수 없기에 sum()보다는 chain()을 쓰지 않을까 싶다.
덧. Numpy
외부 라이브러리를 제외하고 표준 라이브러리만 생각하다 보니 Numpy를 깜빡했다.
list_of_list를 ndarray객체로 바꾸어 reshape()메서드와 flatten()메서드를 실행한 결과를 확인해보자.
import numpy as np
list_of_lists = [[x, 0] for x in range(10000)]
n_lol = np.array(list_of_lists)
%timeit n_lol.reshape(-1)
# 1000000 loops, best of 3: 768 ns per loop
%timeit n_lol.flatten()
# 1000000 loops, best of 3: 1 µs per loop
itertools.chain()보다 수백배 빠르다는 것을 알 수 있다.
결과 비교 그래프
성능들을 한눈에 알아보기 쉽게 하기 위해 matplotlib를 통해 그래프로 시각화 시켜주었다.
그래프를 생성하는 Jupyter 코드
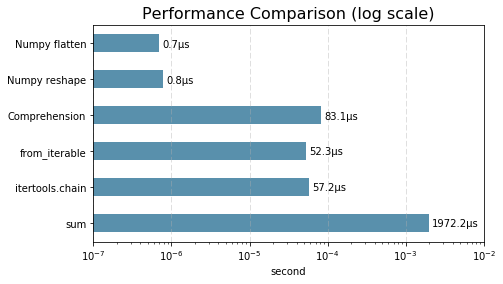 log스케일의 그래프임으로 x축에서 1칸의 차이는 실질적으로 10배의 차이다.
log스케일의 그래프임으로 x축에서 1칸의 차이는 실질적으로 10배의 차이다.
Numpy와 itertools의 차이는 약 100배, Numpy와 sum()의 차이는 1000배 이상이다.