winterjung blog
gunicorn으로 flask에서 동시에 여러 요청 처리
flask 앱 내부적으로 blocking 작업이 있다고 할 때, A 클라이언트가 해당 API를 호출하면 B 클라이언트 요청은 A의 요청이 다 처리될 때 까지 기다린 후에야 처리되기 시작한다. 때문에 외부 API 호출(requests.get), 파일 읽기 쓰기(fp.write, db.query)등의 IO 작업이나 오래걸리는 계산을 수행하는 API가 있을 때 이를 신경써줘야한다. 이 글에서는 gunicorn을 통해 flask 앱이 여러 요청을 동시에 처리할 수 있는 방법을 알아봤다.
gevent.pywsgi.WSGIServer이나aiohttp.web.Application으로 flask 앱을 감싸는 방법은 고려하지 않았다. 더불어 sync, async, blocking, non-blocking의 구분 또한 다루지 않았다.
요약
flask 앱을 gunicorn으로 실행하고 CPU bound 작업을 위한다면 -w 옵션(number of worker processes)을, IO bound 작업을 위한다면 --threads 옵션(number of worker threads)을 신경쓰면서 기본적으로 -k 옵션(worker class)을 gevent 등의 async worker로 설정하는 것을 추천한다.
-w는 워커의 개수를 결정하며 독립적인 프로세스로 flask 앱이 실행된다.--threads는 각 워커마다 가질 스레드 개수를 결정하며 만약-w 4 --threads 4옵션을 사용했다면 한번에 16개의 IO를 처리할 수 있다.- CPU bound 작업은 물리적 코어 수, IO bound 작업은 논리적 코어 수에 의존한다. 만약 물리적 코어가 2개인 머신에서 CPU bound 작업을 처리할 때
-w를 2로주나 4로주나 유의미한 차이가 없으며 오히려 오버헤드가 발생한다. 공식 문서에서 권장하는 워커와 스레드의 개수는 2 * $NUM_CPU + 1이다.
worker class를 gaiohttp로 설정할 땐 aiohttp 라이브러리 버전이 1.3.5 이하여야한다. [gaiohttp를 사용하기 위한 다른 방법]도 소개되어있다.
Synchronous flask
flask앱은 기본적으로 동기적(synchronous)이다. 그렇기에 다음과 같은 API를 호출할 때 A 클라이언트의 요청을 먼저 호출하고 있다면, B 클라이언트의 요청은 앞선 요청을 다 처리하고 결과를 반환해준 다음에야 처리되기 시작한다.
# test.py
@app.route('/')
def sync():
print('start')
time.sleep(5)
print('finish')
return 'done'
# A request
# A: start
# (after 1 second)
# B request
# (after 4 second)
# A: finish
# B: start
# (after 5 second)
# B: finish
Celery를 사용한다면
celery는 메시지 패싱 방식의 분산 비동기 작업 큐로 pdf 변환, audio render등의 오랜 시간이 걸리는 작업들을 백그라운드에서 비동기적으로 처리한다. 유저한테 처리 결과를 즉시 반환할 필요가 없을 때 사용할 수 있지만 이 역시 뷰 함수의 처리가 다 끝날 때 까지 다른 클라이언트의 요청은 처리되지 않는다.
테스트
테스트에 쓰인 flask 앱은 다음과 같이 구성되어있다. 이는 Github에 올려둔 blocking_flask.py 코드에서도 확인 가능하다.
/request: IO bound 작업으로 5초 동안 외부 API를 호출결과를 기다린다./sleep/<int:count>: 스레드를 count만큼 일시중지 시킨다./compute/<int:count>: CPU bound 작업으로 주어진 count만큼 계산한다.
테스트 도구로는 apache benchmark tool인 ab를 사용했으며 명령어는 $ ab -n 32 -c 16 127.0.0.1:8000/$ENDPOINT로 통일했다.
사용한 gunicorn 명령어는 다음과 같으며 간단한 스크립트를 작성해 테스트했다.
$ gunicorn blocking_flask:app -w $NUM_WORKER --threads $NUM_THREADS -k $WORKER_CLASS- $NUM_WORKER: 1(default), 2, 4
- $NUM_THREADS: 1(default), 2, 4
- $WORKER_CLASS: sync(default), gevent, gaiohttp
테스트 디바이스의 cpu는 $ systemctl hw로 확인했고 물리적 cpu는 2개, 논리적 cpu는 4개다.
Test code에서 보이듯이 Real world 예제와는 거리가 멀다. 보다 실제 환경에 가깝게 하려면 SQLAlchemy등을 이용한 query, 내부 네트워크로 묶인 서버간의 통신 등을 고려해볼 수 있겠지만 여기서는 httpbin.org를 통한 IO 테스트로 일반화했다.
결과
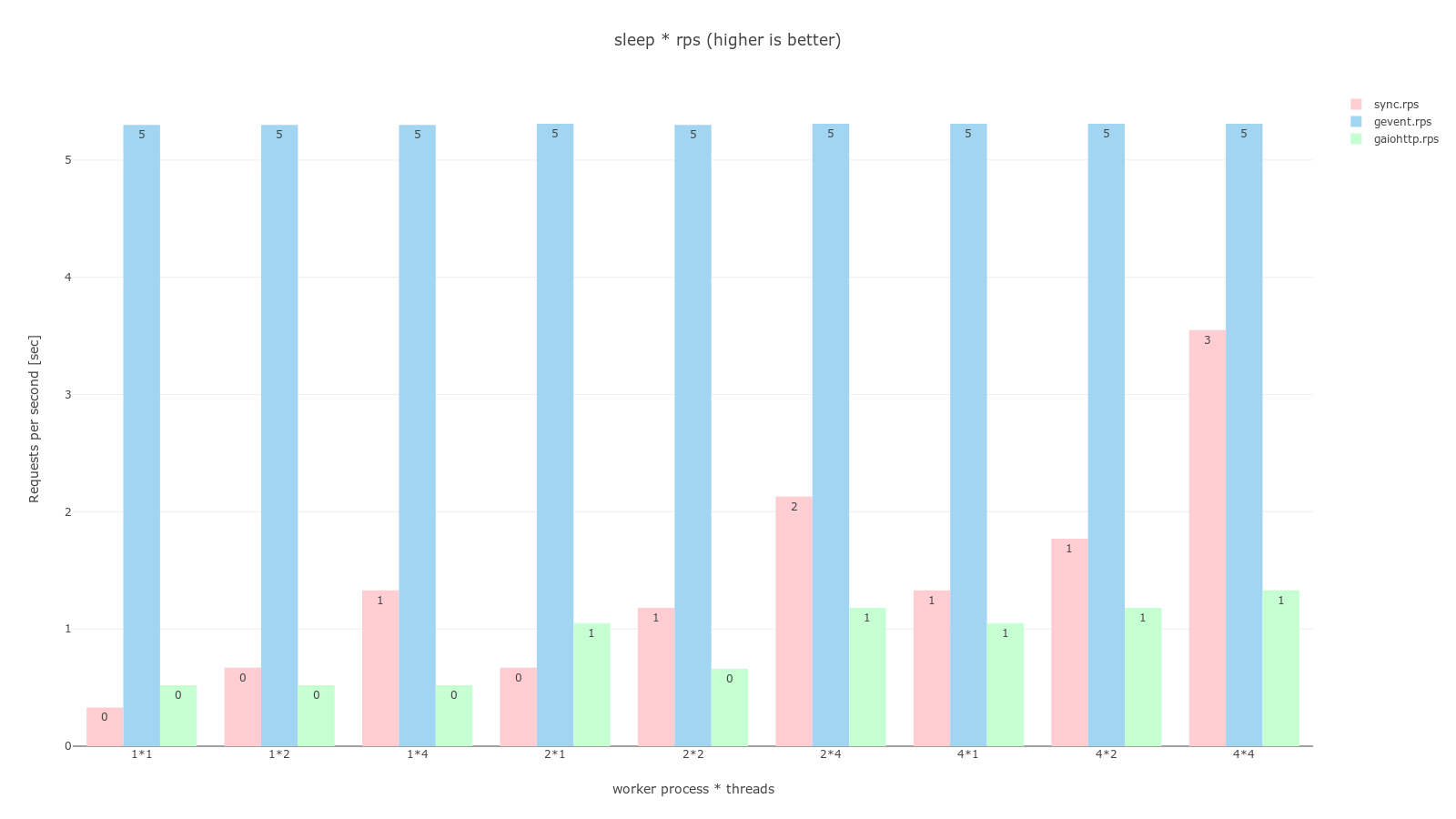
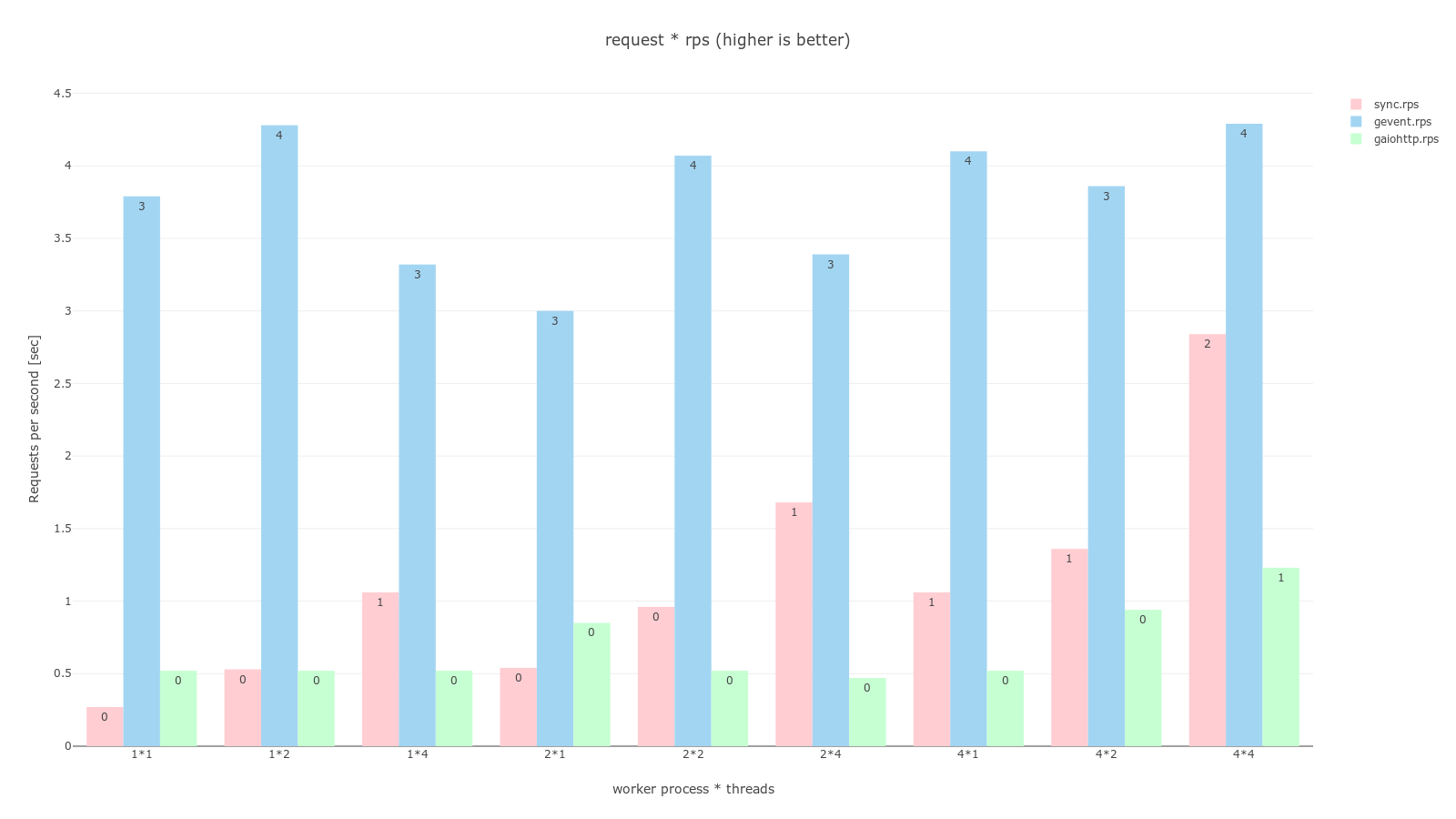
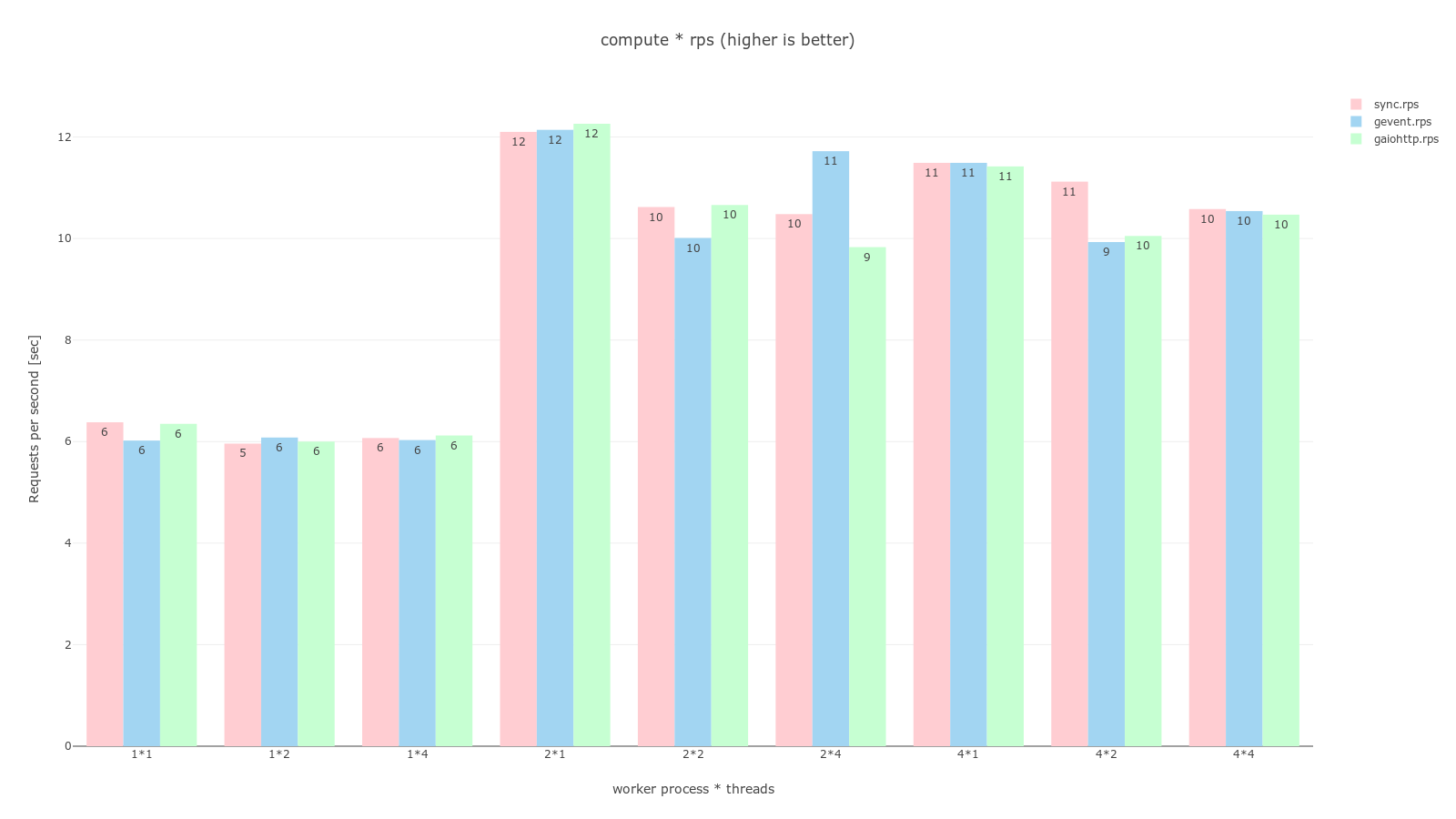
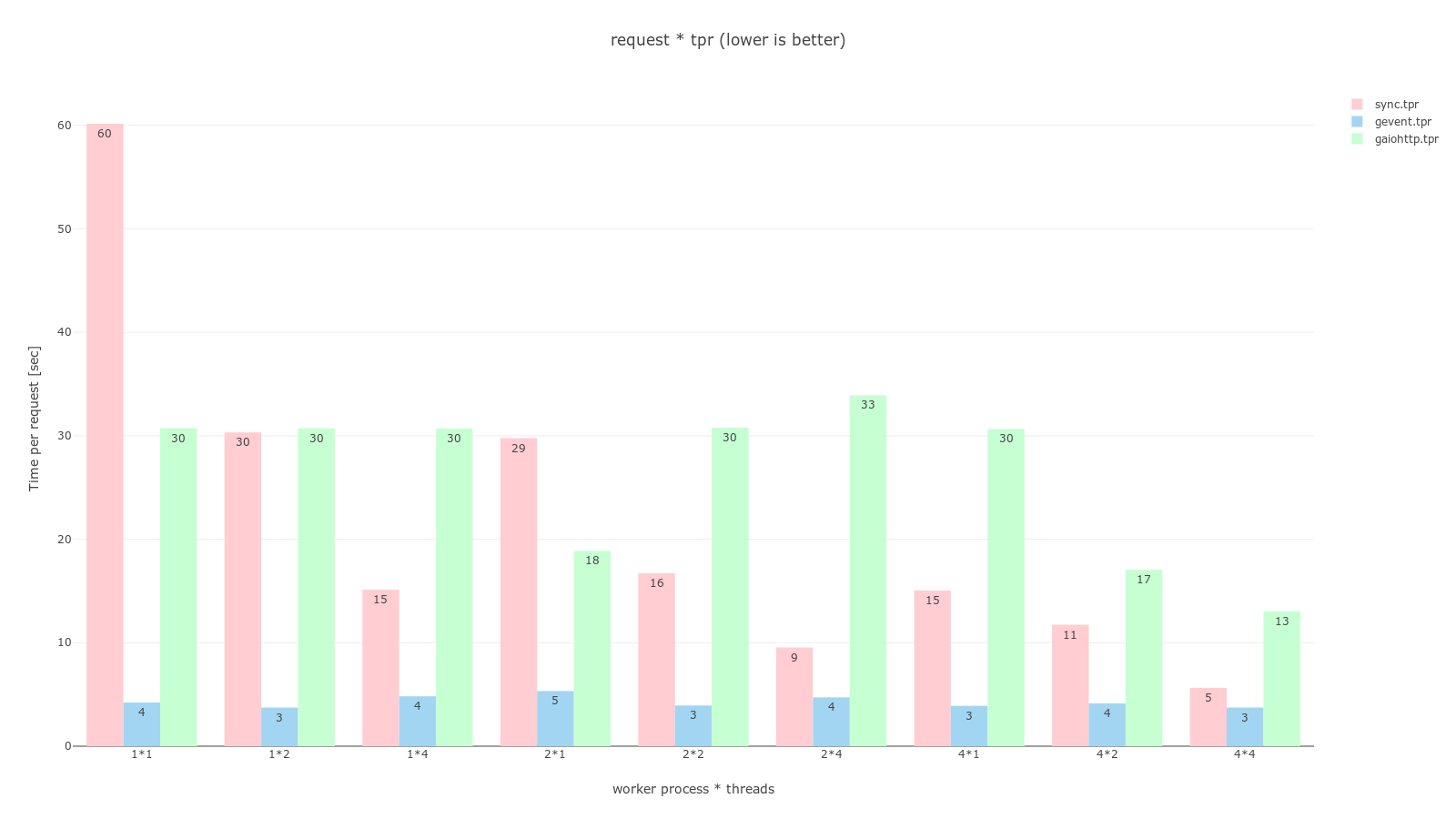
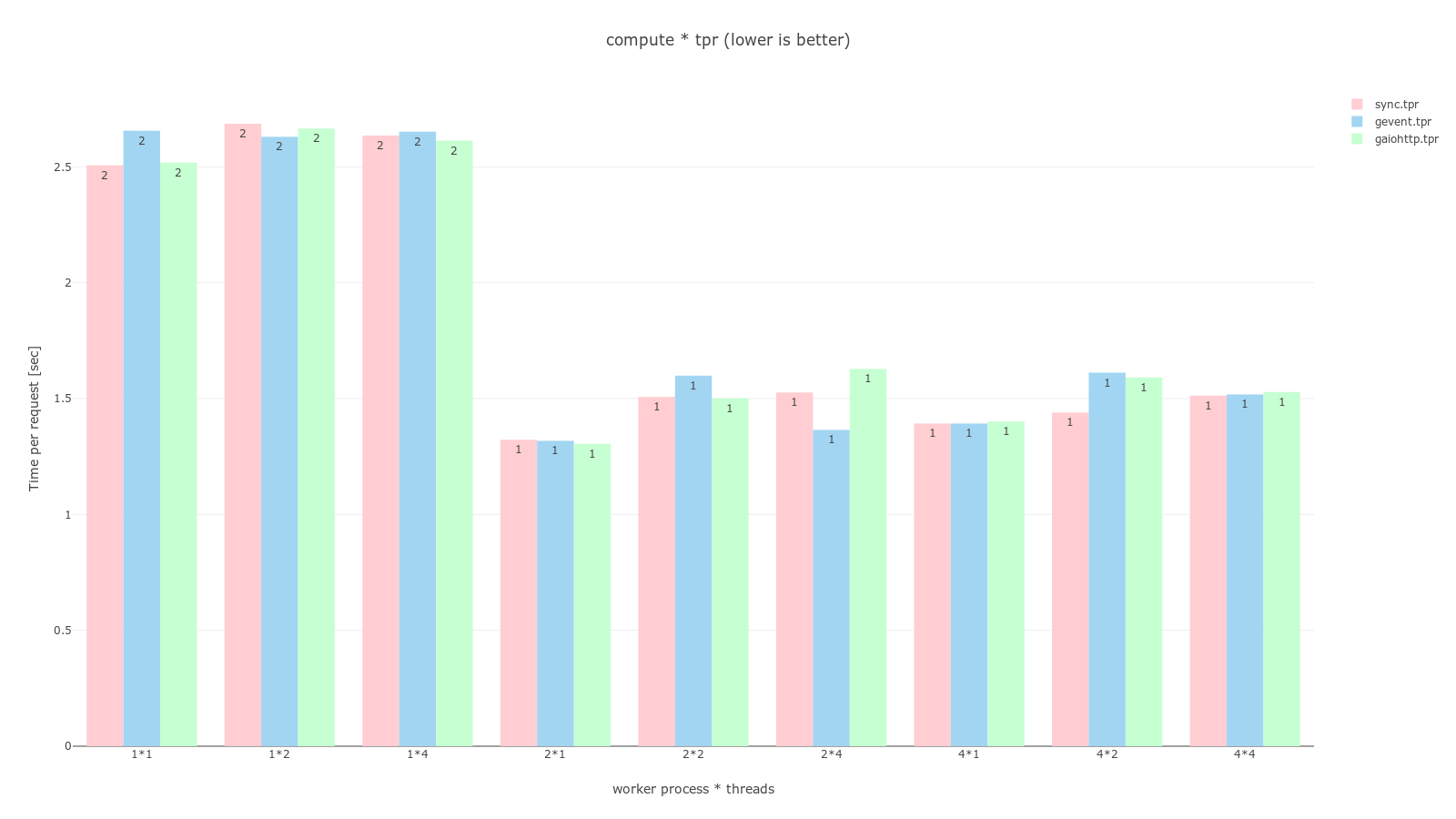
pandas, plotly를 이용해 그래프로 그렸으며 과정은 jupyter notebook 코드에서 확인할 수 있다. 공통적으로 분홍색은 sync, 하늘색은 gevent, 연녹색은 gaiohttp worker이며 RPS는 높을수록 좋고, TPR은 낮을수록 좋다.
Request per second (클릭시 커짐)
Time per request (클릭시 커짐)
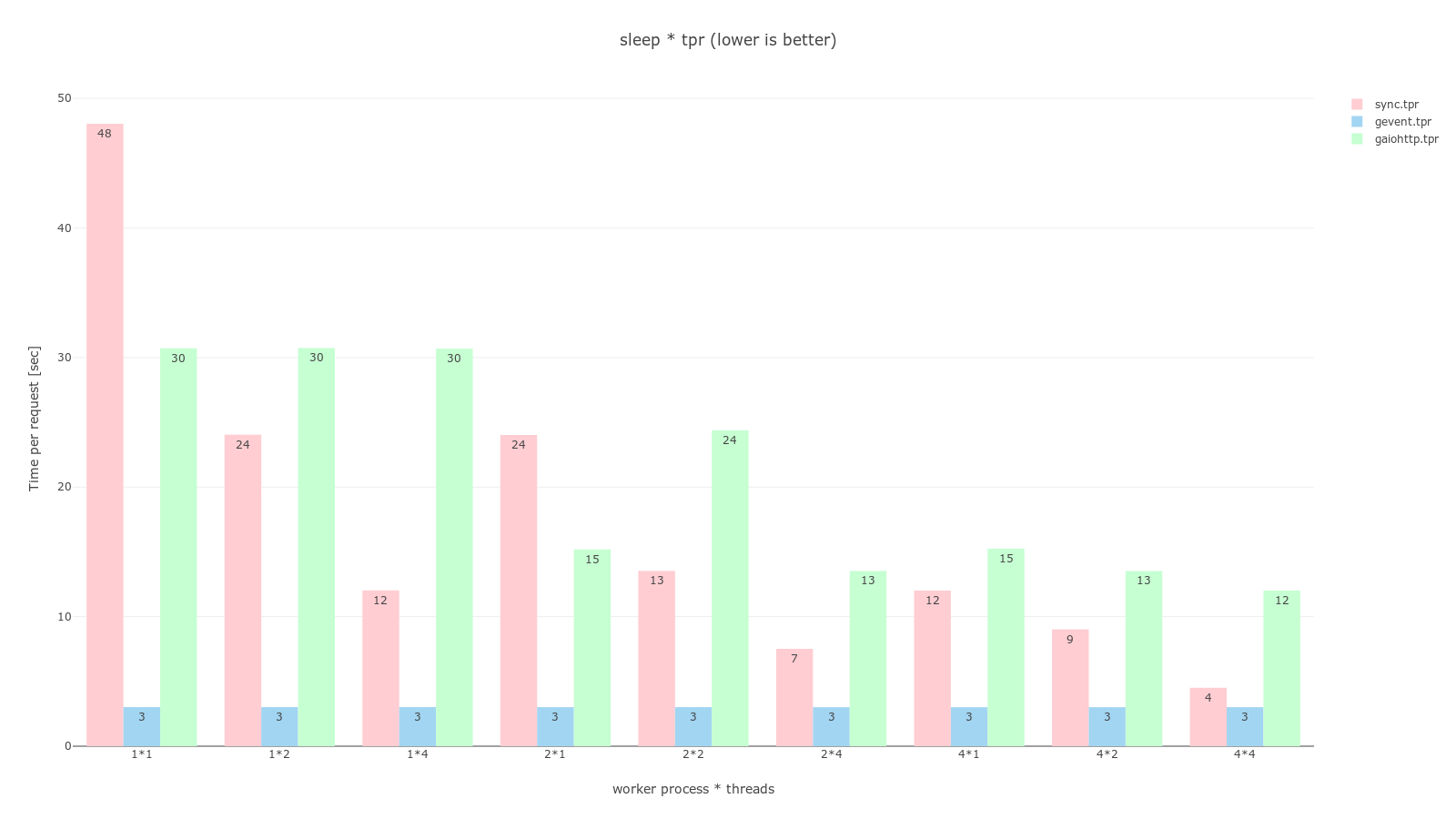
결과를 보며
ab -n 32 -c 16으로 동시에 16개의 요청을 2번 보냈다는걸 생각해보면 worker class를 sync로 설정하는 것은 process, thread가 몇개든간에 최악의 결정임을 알 수 있다. 더불어 sleep * tpr 그래프에서 sync worker는 worker 개수와 thread 개수가 늘어날 수록 처리 시간이 반비례 하고있음을 볼 수 있다.
async worker로 gevent와 gaiohttp를 비교해보면 gaiohttp는 sync보다도 안좋은 결과를 보이고 있다. 개인적으로 외부 API를 호출하는 request 테스트에서라도 gaiohttp가 좋은 결과를 보여줄줄 알았는데 의외의 결과였다.
gevent는 compute에선 다른 worker와 동일한 결과를, 다른 두개의 테스트에서는 다른 worker를 압도하는 결과를 보이고 있다. 실제로 ab -n 200 -c 200 명령어로 비공식 테스트를 실행했을 때도 모두 동시에 처리해버리는 결과를 보이기도했다.
compute는 다른 두개의 테스트와 다르게 CPU bound 작업을 수행하는데 그래프에서 볼 수 있듯이 이는 물리적 코어 개수에 영향을 받아 worker 개수가 2개든 4개든 비슷한, 4개일 때는 오히려 오버헤드로인해 더 느려진 결과를 보여주고있다. 개인적으로 이런 cpu bound 작업은 celery를 사용해 다른 머신으로 넘겨서 처리하는게 좋을 것이라 생각한다.
마치며
이 글을 쓰기 전 수행했던 테스트는 flask와 gunicorn을 조합할 때 어떤 옵션이 가장 좋은가에 중점을 두었기 때문에 flask는 기본적인 로직만 구현했고 머신의 성능이나 실무에서 쓰일법한 동작을 고려하지 않았다. 원래는 워커는 많을수록 좋겠고 스레드도 마찬가지겠는데 워커 클래스는 뭘 선택하지에서 출발했기에 아무래도 부족한 점이 있을 수 있다. 그래도 flask 앱을 gunicorn으로 배포하자고 결정할 때 작은 도움이 되길 바라며 잘못된 정보, 오타 혹은 보완할 점이 있으면 트위터, 메일 등으로 알려주시면 감사하겠습니다.